

Why use o3-pro?
Not like general-purpose fashions like GPT-4o that prioritize velocity, broad information, and making customers feel good about themselves, o3-pro makes use of a chain-of-thought simulated reasoning course of to commit extra output tokens towards working by way of advanced issues, making it typically higher for technical challenges that require deeper evaluation. However it’s nonetheless not good.
Measuring so-called “reasoning” functionality is difficult since benchmarks will be straightforward to sport by cherry-picking or coaching knowledge contamination, however OpenAI stories that o3-pro is standard amongst testers, at the very least. “In knowledgeable evaluations, reviewers constantly want o3-pro over o3 in each examined class and particularly in key domains like science, training, programming, enterprise, and writing assist,” writes OpenAI in its launch notes. “Reviewers additionally rated o3-pro constantly increased for readability, comprehensiveness, instruction-following, and accuracy.”
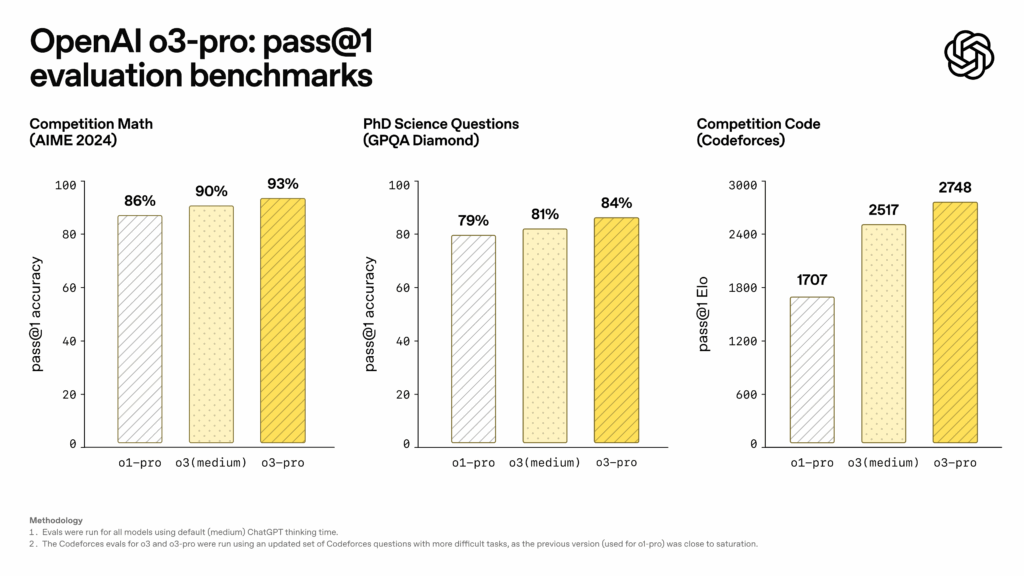
OpenAI shared benchmark outcomes displaying o3-pro’s reported efficiency enhancements. On the AIME 2024 arithmetic competitors, o3-pro achieved 93 p.c move@1 accuracy, in comparison with 90 p.c for o3 (medium) and 86 p.c for o1-pro. The mannequin reached 84 p.c on PhD-level science questions from GPQA Diamond, up from 81 p.c for o3 (medium) and 79 p.c for o1-pro. For programming duties measured by Codeforces, o3-pro achieved an Elo score of 2748, surpassing o3 (medium) at 2517 and o1-pro at 1707.
When reasoning is simulated

It is simple for laypeople to be thrown off by the anthropomorphic claims of “reasoning” in AI fashions. On this case, as with the borrowed anthropomorphic time period “hallucinations,” “reasoning” has turn out to be a time period of artwork within the AI trade that mainly means “devoting extra compute time to fixing an issue.” It doesn’t essentially imply the AI fashions systematically apply logic or possess the flexibility to assemble options to really novel issues. For this reason Ars Technica continues to make use of the time period “simulated reasoning” (SR) to explain these fashions. They’re simulating a human-style reasoning course of that doesn’t essentially produce the identical outcomes as human reasoning when confronted with novel challenges.